
Introduction
In today’s fast-paced digital world, accessing the right information at the right time is a key competitive advantage. This is where large language models (LLMs) come into play. These advanced AI systems can understand and generate human-like text, making them highly relevant for users and providers of document management systems alike. However, accessing proprietary content based on this technology is not quite straightforward. In this blog post, we discuss Retrieval Augmented Generation (RAG), the basic technology that enables you to access vast amounts of documents with state-of-the-art AI technology – safely. In doing so, we are taking the look under the hood (or bonnet, if you so prefer) of d.velop’s latest innovations in the area of modern document management. But before we start, let’s anchor our discussion in a real-world problem, right on your desk:
Imagine you are working on an important project and need to quickly find specific information buried within your company’s extensive document repository. Traditionally, this might involve manually specifying a search query, opening countless files, scanning through them, reading paragraphs in detail, all the while keeping track of your findings. This can be both time-consuming and frustrating. But what if there was a smarter way to get exactly what you need instantly?
What does Retrieval Augmented Generation (RAG) mean?
Enter Retrieval Augmented Generation (RAG), a cutting-edge technology that combines the power of LLMs with intelligent retrieval mechanisms to deliver concise answers quickly – all grounded in your own data. Think of it as having a knowledgeable assistant who not only understands your questions but also knows exactly where to look for the answers within your document management system.
Read on to discover how Retrieval Augmented Generation can empower your organization by making critical information effortlessly accessible—right when you need it most! So let’s get going and build our own RAG pipeline, shall we?
Large Language Models – Autocomplete on Steroids
To build a virtual assistant that answers your questions, we have to establish a basic understanding of the inner workings of an LLM first. So, imagine you’re using your smartphone and typing a message. As you start with “Actions speak louder than…”, your phone’s auto-complete feature suggests “words” to finish the proverb. This is a simple example of how a language model works—predicting and generating text based on patterns it has learned from vast amounts of data. Essentially, it’s like a highly advanced version of your phone’s auto-complete, but capable of much more complex tasks.
When tasked to generate longer texts, an LLM-based system will just iterate the process. So, when prompted with the phrase, “When shall we three meet again? ,,,” it will first predict “In”. Subsequently, this output is appended to the prompt leading to “When shall we three meet again? In…” Iterating this process will eventually lead to the opening scene of Shakespeare’s Macbeth “When shall we three meet again? In thunder, lightning, or in rain?”.
So LLMs are extremely capable at generating plausible text given a prompt. Because they have been trained on a vast amount of knowledge from the internet, they also excel at answering arbitrary questions. However, they sometimes do so “too well”. They will make up stuff. We call this a hallucination. This is problematic because it will not always be apparent. Moreover, an LLM does not have access to your company’s proprietary data – and for a good reason.
How to Integrate Your Proprietary Content?
This is where Retrieval-Augmented Generation (RAG) comes into play. RAG combines the strengths of a pre-trained LLM with advanced retrieval mechanisms You can think of the resulting system as having an incredibly knowledgeable assistant who not only understands your questions but also knows exactly where to find the most relevant information in your d.velop documents repository. The following figure gives you a schematic, high-level overview of what we are trying to build:
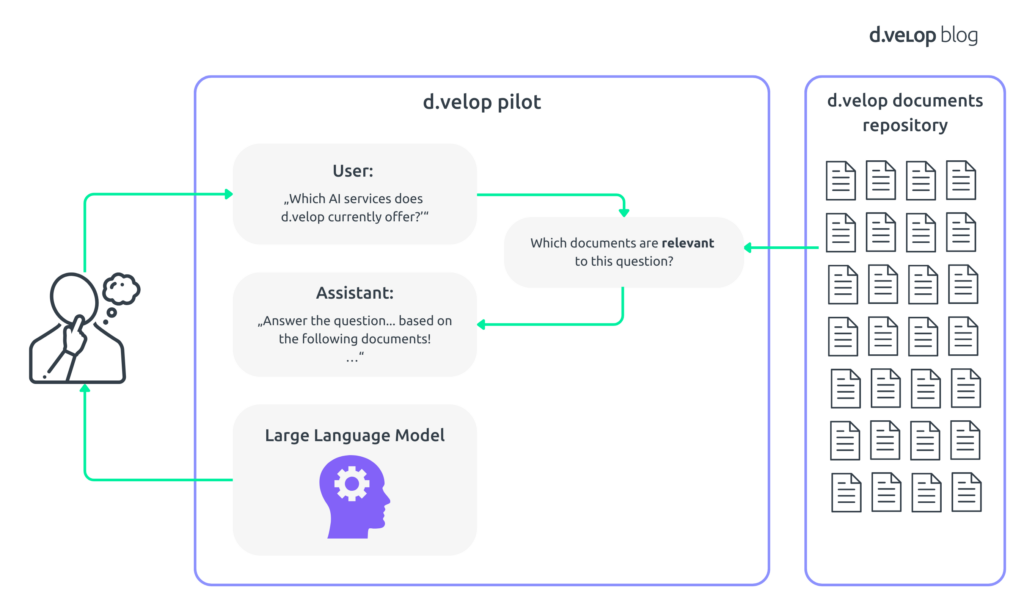
Here’s how it works: When you ask a question or make a query, the system first searches through your organization’s documents to retrieve relevant pieces of information. The AI then uses this retrieved data to generate accurate and contextually appropriate responses. This process ensures that the answers you receive are both precise and tailored to your specific needs.
In essence, Retrieval-Augmented Generation transforms how we interact with our digital content by making it more accessible and actionable. Whether you’re drafting reports, preparing presentations, or making strategic decisions, RAG empowers you with timely and relevant information at your fingertips—making digitization projects more efficient and effective than ever before.
How Do We Know “Relevant Content”?
With the basic pipeline established, we must efficiently determine which content is relevant to a specific question or query. Here’s where it gets interesting: Instead of training the LLM on all your company’s documents – a process that would be time-consuming, expensive, and risk exposing your company’s IP to third parties – RAG uses a smarter method.
In simple terms, RAG uses advanced mathematical techniques to understand and process language. At its core are word embeddings—numerical representations of words that capture their meanings based on context. Let’s break this down in a way that’s easy to grasp.
Because computers are good at numbers but not quite as good on language, our first order of business is to establish a way of “turning words into numbers”. Ideally, this transformation captures the meaning of the underlying words. While the details of this process incorporate quite intricate mathematics, we present a high-level intuition here. So, let’s introduce the key concept of “word embeddings”.
What Are Word Embeddings?
Think back to your school days when you learned about vectors—those little arrows pointing in different directions. In the world of natural language processing (NLP), we use these vectors to represent the meaning of words. Essentially, we train a language model, a specifically trained neural network, to map a word or phrase to a high-dimensional vector. We call this model the embedding model. The following image shows the basic intuition behind this process:
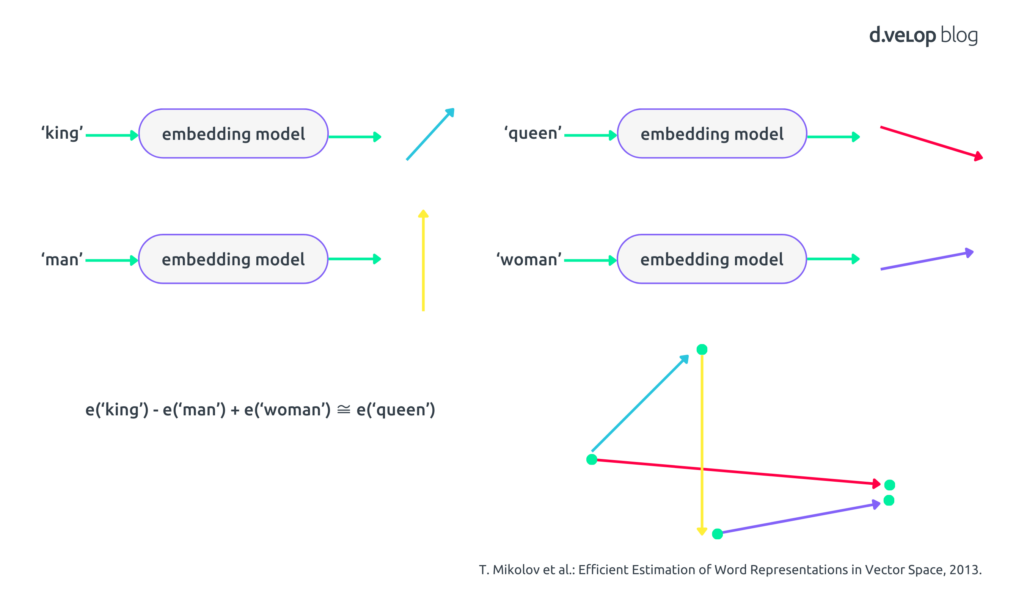
To build some intuition, consider the words “king” and “queen.” If we take the embedding vector for “king” (turquoise) subtract the vector for “man” (yellow) and add the vector for “woman” (purple), we end up with something very close to the embedding for “queen” (red). This canonical example shows how these vectors can reveal deep insights into the semantics of words. For a more elaborate, theoretically sound discussion, we refer the interested reader to the seminal paper by Mikolov et al. [T. Mikolov et al.: Efficient Estimation of Word Representations in Vector Space, 2013].
From word embeddings, it is only a little step to document embeddings: Essentially, you can use the same underlying mechanics to compute vectors that represent the meaning of phrases or entire documents. In practice, we take a middle-of-the-road approach. In order to create meaningful vector representations for longer text passages, we split up each document into multiple chunks and compute a vector for each of these chunks. For brevity of explanation, however, we will use the term document embeddings and phrase the following discussion as if we had a single embedding vector per document.
How to Compute Relevance?
Now that we understand word and document embeddings, let’s see how they help us define relevance. When you ask a question or enter a search query, we can embed that query. This will result in a vector that captures the essential meaning of your question. We can do the same for every document, resulting an embedding vector per document. And because both vectors capture “meaning”, we can compare them. This is done using the basic cosine-similarity metric. So essentially, we equate relevance between a document and your query to the angle between the respective embedding vectors, like so:
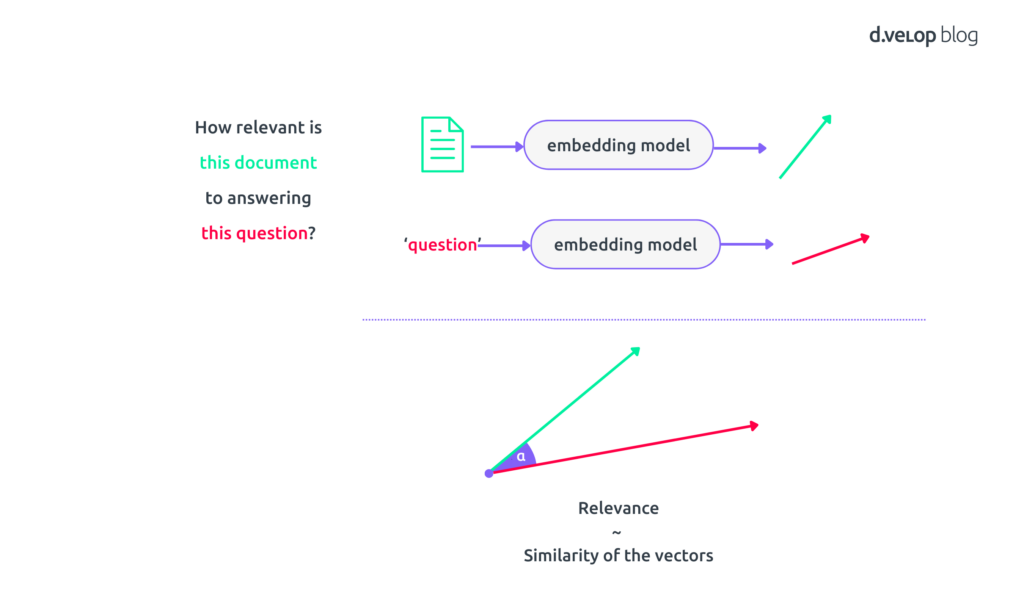
If the vectors are very similar, i.e., point in the same direction, it means that the respective document is highly relevant to your query. If they’re not similar, then that document isn’t what you’re looking for.
Efficient Handling of Document Queries
Imagine you have a massive library of documents – contracts, reports, emails, you name it. Computing embedding vectors for all these documents interactively is prohibitively expensive computationally. If you compute the vectors for all documents at query time, queries will take forever.
Fortunately, documents do not change all that often. Hence, we can precompute embeddings for documents. We only need to recompute them whenever a new document is added to your repository, or an existing one is updated. We store all these vectors in a purpose-built vector database or vector index. The database engine offers fast (approximate) retrieval of vectors. Specifically, it is able to find the most similar vectors to a given query vector.
Digital Document Management Easy Explained
Key features, implementation steps, and AI insights – all in one practical guide.
Streamlined Document Query Handling with RAG: Transforming Questions into Relevant Answers?
Let’s say you’re looking for specific clauses in a contract or particular details in an annual report. Here’s how the system establishes the relevant input text to answer that question:
- Query Transformation: Your question is transformed into its own embedding vector.
- Database Query: The system then uses this vector to query the vector database.
- Result Computation: By efficiently computing the similarity between query vector and pre-computed document vectors using cosine similarity, the system identifies which chunks are most relevant.
To round out the process, your input question and the relevant documents are folded into a prompt. This prompt essentially asks for an answer to the question provided the information provided in the context documents. This prompt is carefully constructed a) to best use the capabilities of the underlying LLM and b) to ground the answering process in the documents and thus minimize the risk for hallucinations. The entire process, including the details discussed above, is depicted in the following schematic.
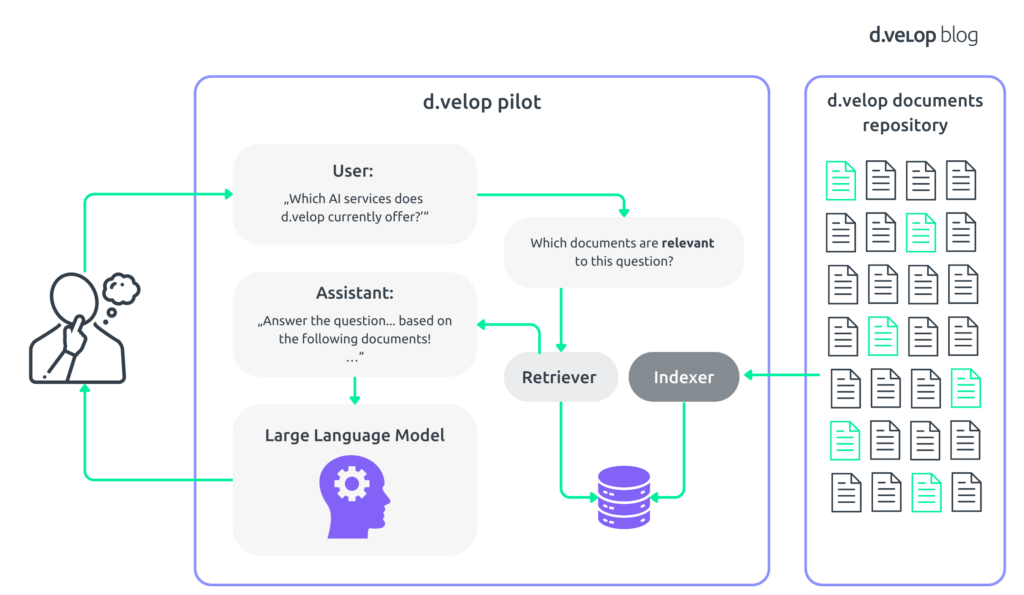
This is your standard retrieval augmented generation pipeline. The acronym fits well. The final generation stage, responsible for phrasing an answer to your initial question, draws on a prior retrieval step that establishes a subset of documents for the necessary facts.
Putting it into Production
Unfortunately, a vanilla implementation is sufficient for demos but not yet ready for 24/7 use in a production environment. To this end, ensuring security and privacy is paramount.
Regulated Information Access
Imagine you’re working on a sensitive project within your company’s d.velop documents. Not everyone should have access to all documents related to this project. In fact, the permissions can be quite complex. Yet, an unlimited RAG pipeline will readily answer any question about anybody.
The ability to design and enforce detailed, fine-grained access rights has always been a staple of d.velop documents. Thus, our RAG implementation builds on that work. We ensure that when a user queries the system, the AI only retrieves documents they are authorized to view.
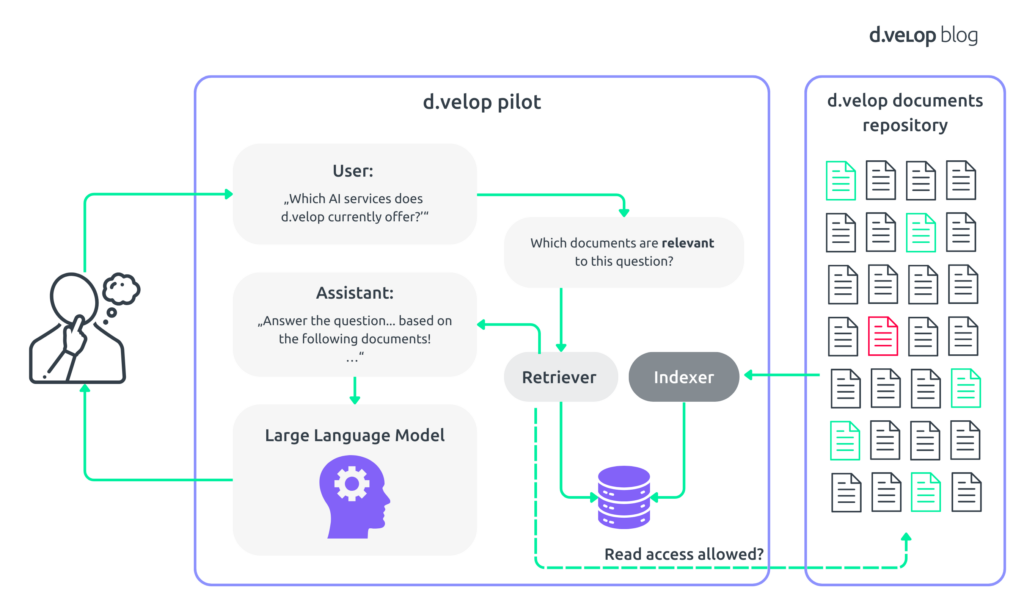
In the above example, Sarah, a member of the marketing team known for her curiosity, can ask a question targeting your sensitive project. However, since she is not on the project team, Sarah doesn’t have the right to view your proposal and related documents. Hence, the system will answer Sarah’s question with a generic remark that it was unable to find anything meaningful on the topic.
In summary, respecting access rights upon retrieval, your employees only see what they are allowed to see – keeping sensitive information secure and ensuring compliance with company policies.
Keeping your Data
By their very definition, large language models are, well, Large. Consequently, we rely on external cloud offerings such as Microsoft Azure OpenAI services, Amazon Bedrock, or Anthropic and their respective APIs to implement the heavy lifting.
This begs the question of who might have access to your data? Rest assured. We take your privacy seriously. Document indexing—preparing documents for retrieval—selectively and securely prepares your files. Users have full control over what gets indexed, and everything else can remain untouched. Your data is always encrypted, both at rest and in transit, including the vector database.
Moreover, we double-check each LLM offering’s data protection clauses carefully. Among other things, we ensure that we only include offerings which explicitly do not use your data for training purposes. Finally, we only include offerings that are hosted inside the EU to prevent third-country transmissions outside the realm of the EU-GDPR.
Conclusion
So, there you have it. A working RAG system that ensures fast data access and respects your data privacy and security concerns. And now that we have a working system on the drawing board, let’s bring this down to earth with some concrete examples:
Legal Departments: Imagine you’re part of a legal team needing to find mentions of a specific clause across thousands of contracts stored in your d.velop documents repository. With RAG, you simply type your query in natural language (“Find contracts featuring ‘unlimited liability’ clauses.”), and within moments, you get precise results without having to sift through each document manually.
Customer Support: If you’re handling customer inquiries about product manuals or service agreements, RAG can help you quickly pull up relevant sections from extensive documentation based on customer questions, allowing for faster and more accurate responses.
R&D Teams – Imagine you’re working on a project proposal and need background information on previous similar projects. Your RAG-enabled document repository provides you with highly relevant documents from past projects. Moreover, it does not only point you at documents: It phrases a short, concise answer for you to work with. The documents are there for in-depth research should you need them. Thus, for those conducting research across numerous scientific articles, white papers, and reports, RAG enables quick extraction of pertinent data points related to their current research topic – saving you hours of manual searching and ensuring you have comprehensive data at your fingertips.
💻Book Software Demo
Experience the power of d.velop’s software with a personalised live demo, easily requested with just a few clicks. Watch as the software comes to life before your eyes and ask any questions you may have in real-time.
As you can see, generative AI in general and Large Language Models in particular are transforming the way we do knowledge work. These technologies are here to alleviate the bottlenecks of information access. You ask questions in plain language; the underlying tech does the heavy lifting behind the scenes and delivers to you precise answers swiftly.
With this powerful technology, d.velop documents remains at the forefront of innovation – built on trust and for secure, efficient access to information. We are currently testing our first RAG implementation in a closed beta program. Look forward to the general release in winter! If we have caught your interest, we look forward to your feedback.