
A vital step of Enterprise Content Management is document ingestion, i.e. the processing of incoming documents. Paper documents need to be digitized, data has to be extracted, and – eventually – documents have to be filed and forwarded to downstream processes. If this sounds boring, it’s because it actually is.
Document ingestion is a tedious, highly repetitive task. And done in a classical way, it is highly labor-intensive. Hundreds of hours of manual labor are spent on manual data entry in order to (re-)capture information from paper documents that have started their lives as digital documents in the first place. And if this sounds absurd to you, it’s because it is.
So, what can we do about it? Quite simply, recent advances in artificial intelligence (AI) in general deep learning in particular have brought a massive leap in the capabilities of AI technology. The prowess of AI-based “players” in certain board games, e.g. chess [DeepBlue] or more recently Go [AlphaGo] have become news headlines. Closer to our personal experience, these technological advances have led to innovative services that help in our daily lives, e.g. digital assistants with whom we can converse in natural language [Siri, Alexa, Google Assistant]. So on the one hand, we have a tedious task that we would like to streamline and on the other, we have a technological movement that might help us do just that. The question then is: How exactly can AI support your document ingestion process?
Our central SaaS solution for document ingestion is d.velop inbound scan , or inbound for short. It is a fully featured web application that helps you file your incoming documents. In inbound, we identify three distinct tasks that can be supported by AI technology: document identification, document classification, and information extraction. These are laid out in a sequential pipeline as shown in the image below.
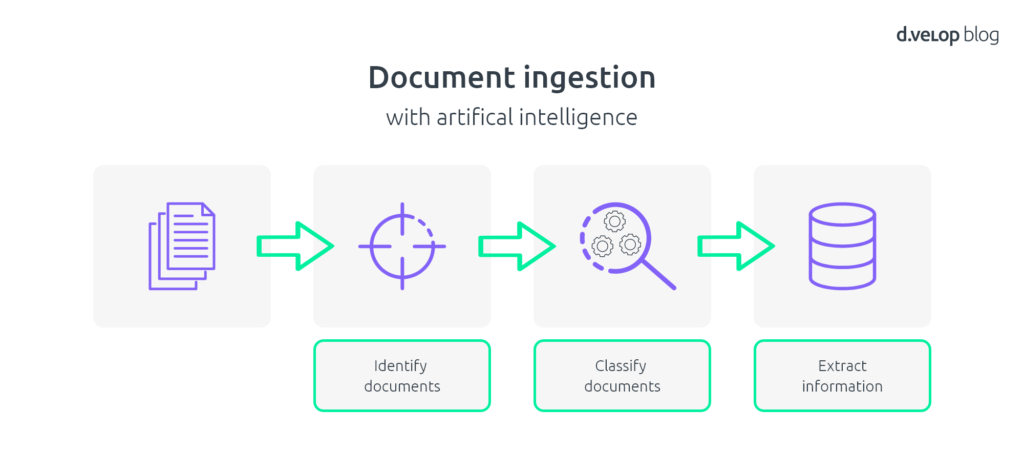
Figure 1 – Schematic view of the document ingestion process and its AI-supported tasks.
Throughout the workflow, our approach is “collaboration over substitution”: quite frankly, we do not believe in laying off highly qualified team members in favor of a fancy computer code. Instead, we believe in a supportive structure where each participant – man and machine – plays to their strengths.
Where are my documents?
The goal of document identification is to split up a stack of scanned pages into logically contiguous documents. Imagine you get your daily stack of mail. You have it all opened and feed it to your document scanner. Out comes a stack of sorted pages that contain today’s worth of inbound mail traffic in digital form. Our first AI service helps you find logical document breaks in this stack. It goes through the stack and analyzes each page. It looks at both the page’s layout and its raw text which has been produced by state of the art optical character recognition. Document breaks identified by the service are fed back to the user interface. This helps you identify individual documents more quickly. Yet, it is meant to support you: you still can verify the computer-generated splits if you choose to do so. In all, this saves you a significant amount of time. The automatic splitting recommendation comes “batteries included” – you don’t need to configure anything, it’s just there. And best of all: over time, the AI service gets better. Every time you correct a suggested document break, the service gets feedback and learns from its mistakes.
What documents am I dealing with?
Once you have retrieved individual documents, it’s time to figure out what they mean. The first, vital step is to classify the documents, i.e. get a first understanding of the broad category the document belongs to. In this step, our next AI service uses advanced natural language processing (NLP) capabilities to figure this out for you and offer a recommendation. Are you looking at an invoice? Or a delivery slip? Or an order? These might look similar, yet the business processes they trigger downstream are vastly different. So having help in telling what’s what is definitely a welcome addon. Again, this addon comes “out of the box”. It’s there. It’s a recommendation. And you can correct it if you feel it did not tag the document right. The document category will not only help you identify the correct downstream workflow. It will also be kept as a document annotation. This enables structured filing and – most importantly – convenient retrieval later on.
What is important about my documents?
So now you know about your documents and what they mean in general. But we are not quite done yet. The by far most tedious part of the workflow is still ahead: information extraction. In this step you want to capture the essential data from the document. Extracting this metadata helps you transform the unstructured data of the document into a concise, structured format that is amenable for downstream processing. For example, an invoice needs to be paid. So you need to figure out who get’s paid for what and how much, among other things. All this data is usually captured by hand, i.e. someone will either copy it from the document and paste it into a data capturing dialog or retype the exact information altogether – obviously a tedious and error-prone way of doing this. However, we got you covered – this time in multiple ways. Using state of the art NLP techniques, our recently launched d.velop document analysis service automatically extracts salient information from your documents. Information items are tagged using a technique called named entity recognition, i.e. the service will look for certain items in your documents that carry a distinct meaning such as an invoice number or a sum total. The fact that these are generically applicable concepts in the context of business documents allows us to train these models in a generic fashion. Your benefit: you can just use the service without any need for manual configuration or up-front training. In addition, our d.velop document reader invoice offers the net benefit of almost two decades of experience in automatic document processing in order to find even more detailed information in invoices. Taken together, these solutions not only help you annotate your data concisely.
What’s next?
Once you completed this step, you are all set: you can file your documents including a rich set of metadata that describes the documents’ categories and contains key pieces of information. AI services have helped you along the way. The information you extracted will be directly usable in subsequent processes. Thus, the AI services that supported you along the way did not only streamline document ingestion; you get an added value from being able to rely on high-quality, pre-extracted information in downstream workflows such as invoice processing. All services mentioned above are available today. If you are interested, we recommend you give them a try right away. For your convenience, all services are neatly integrated into our d.velop documents ultimate edition.
Test d.velop documents easily and risk-free for 30 days completely free of charge
